Managing Operational Challenges in Caching
From Alex Xu at ByteByteGo.
Alex Xu at ByteByteGo recently published “A Crash Course in Caching”.
Introduction
When implementing caching systems, it is crucial to not only choose the best cache strategies but also address the operational challenges that may arise. The following section dives into common caching problems by category and provides insight into how to tackle these challenges effectively.
Reliability Challenges
Cache reliability is important for maintaining stable system performance. Common reliability issues include cache avalanche, cache stampede, and cache penetration.
Mitigating cache avalanche and cache stampede
Caching systems play a crucial role in protecting databases by maintaining high cache hit ratios and reducing traffic to storage systems. Under normal conditions, most read requests result in cache hits, with only a small portion leading to cache misses. By design, the cache handles the majority of the traffic, and the storage system experiences significantly less load.
Cache avalanche and cache stampede are related but distinct phenomena that can occur in large scale systems, causing significant performance degradation or even system-wide outages. Cache avalanche happens when multiple or all cache entries expire simultaneously or within a short time window, leading to a sudden surge in requests to the underlying data store.
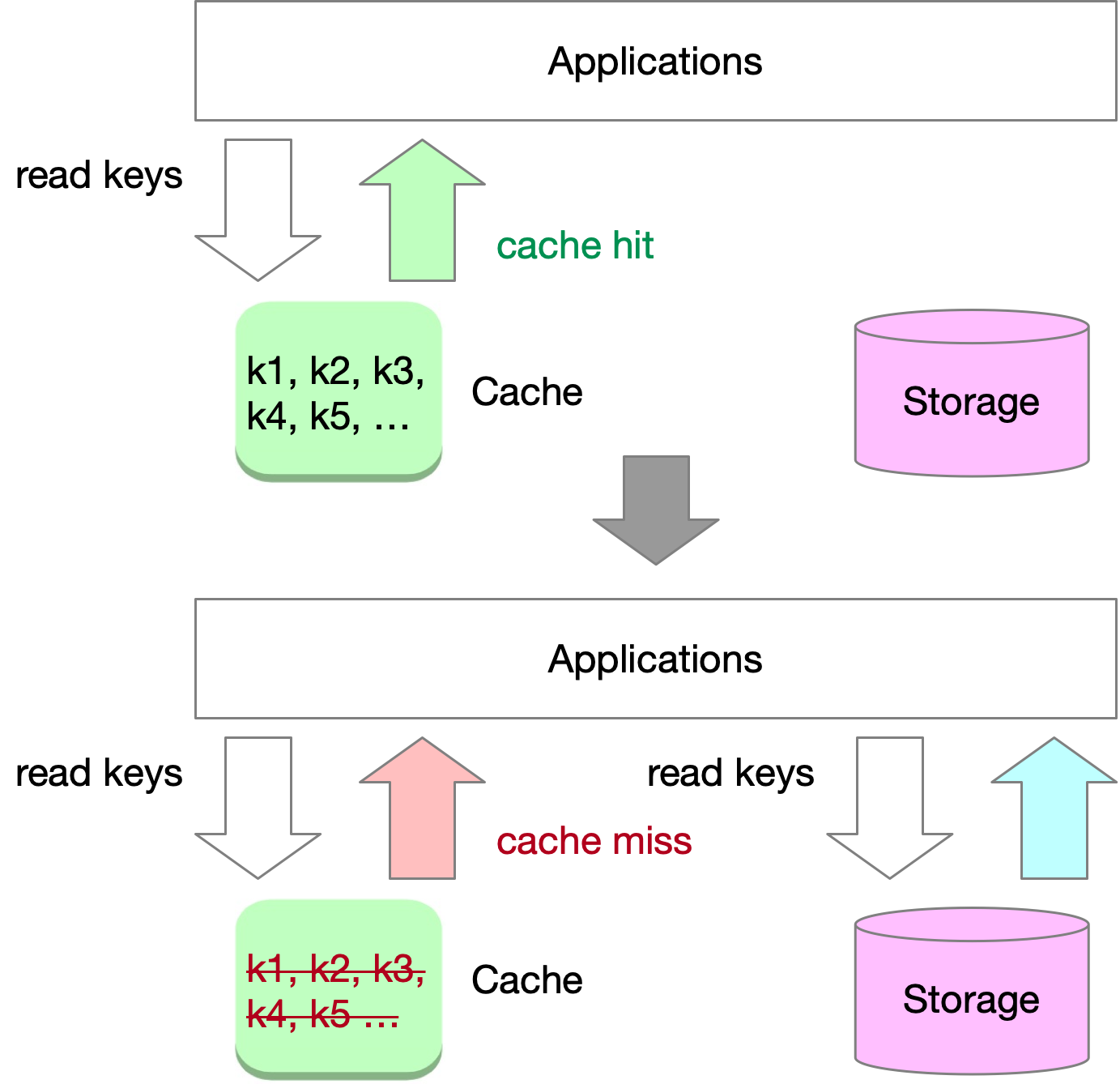
Cache stampede, also known as thundering herd, occurs in large scale systems when a sudden influx of requests overwhelms the system, causing performance degradation or even system-wide outages. This can happen due to various reasons, such as cache misses on popular items, a sudden spike in user traffic, or service restarts after maintenance.
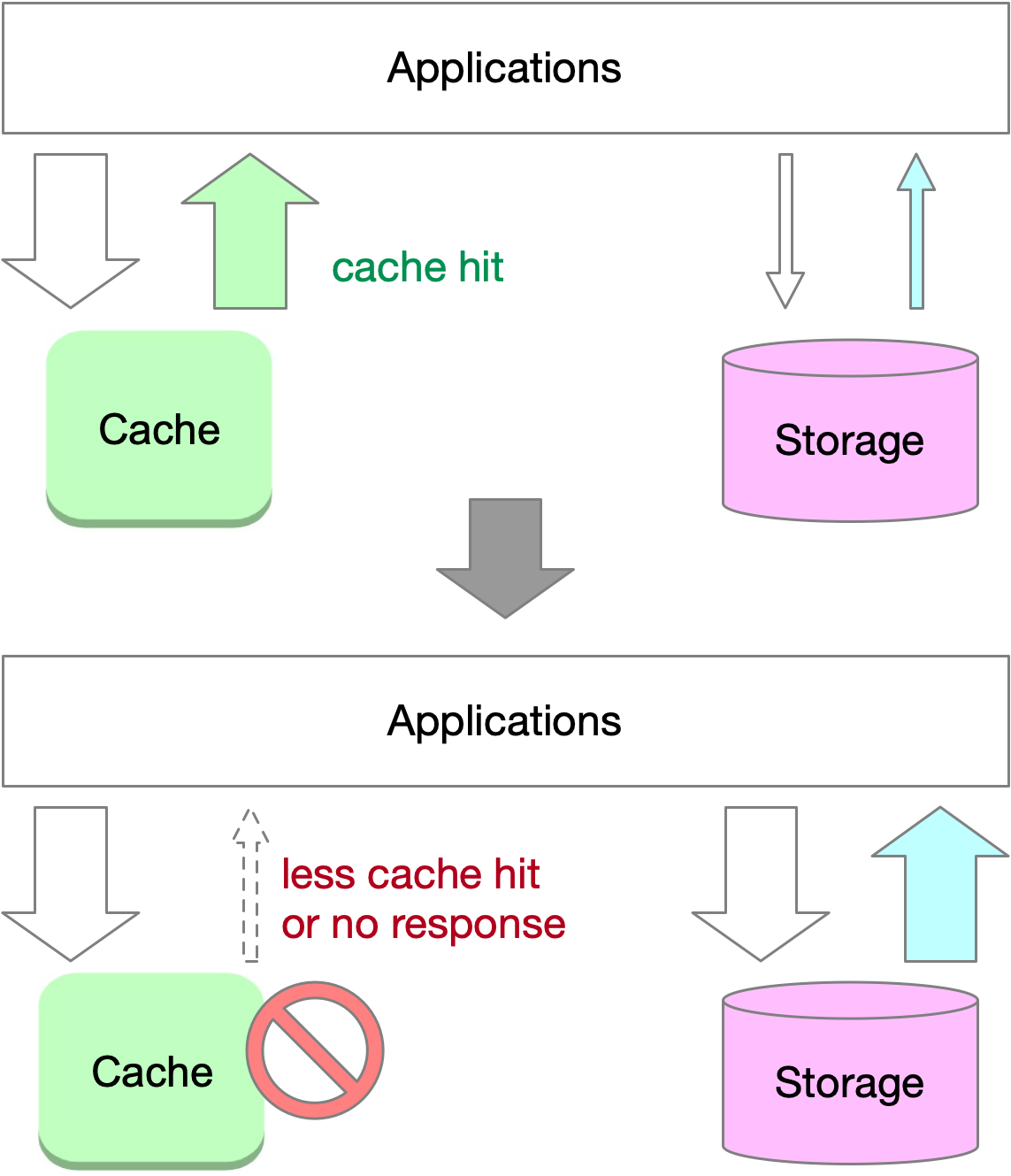
When a cache or part of it fails, a large number of read requests result in cache misses, causing a massive influx of traffic to the storage system. This sudden increase in traffic can significantly reduce storage performance or even lead to system crashes. In this scenario, the failure of the cache serves as a trigger that combines elements of both cache avalanche and cache stampede, resulting in a high-stress situation for the storage system.
Traffic peaks, such as during high-traffic events like Black Friday sales on e-commerce sites in the United States, can also trigger these phenomena. A single cache node might crash due to the increased demand for popular keys, causing these keys to be rehashed to another node, which then crashes as well, eventually leading to the collapse of the entire cache system.
To maintain the stability and efficiency of large scale systems, it is essential to implement strategies that mitigate the risks of both cache avalanche and cache stampede. There are several techniques to help prevent and alleviate the impact of these events.
Staggered expiration
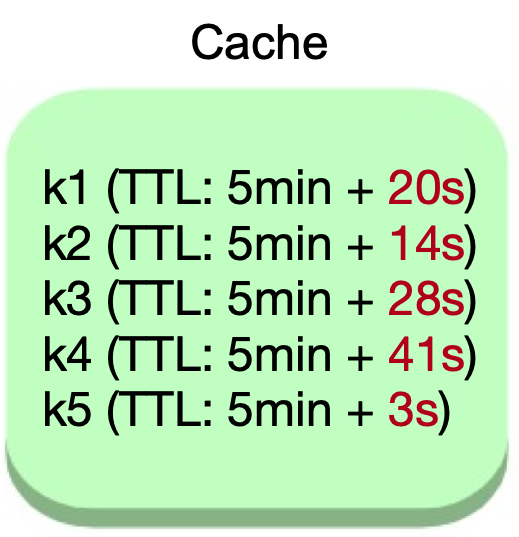
For cache avalanche prevention, use staggered expiration by combining a base time-to-live (TTL) value with a random delta. This approach spreads out the expiration times of cached entries, reducing the likelihood of many items expiring at once.
Consistent hashing
Consistent hashing can be used to distribute cache entries across multiple cache servers evenly. This technique reduces the impact of cache avalanche and cache stampede by sharing the load among the remaining servers and preventing a single point of failure.
Circuit breakers
Implementing circuit breakers in the system can help prevent cache avalanche and cache stampede from escalating into more severe issues. Circuit breakers monitor the system’s health and prevent overloading by stopping excessive requests to the cache and data store if the system is under high stress.
Request rate limiting and load shedding
Employing request rate limiting and load shedding can specifically address cache stampede by controlling the rate at which requests are processed and preventing the system from being overwhelmed. These techniques can be applied on a per-user, per-client, or system-wide basis to maintain stability during high-load situations.
Addressing Cache Penetration Issues
Cache penetration occurs when an application attempts to access non-existent data, bypassing the cache and leading to potential performance issues. When an application requests a non-existent key, it results in a cache miss, followed by a request to the storage system, which also returns an empty result. This bypassing of the cache to reach the backing storage is referred to as cache penetration. If a large number of non-existent key requests occur, it can impact the performance of the storage layer and destabilize the overall system.
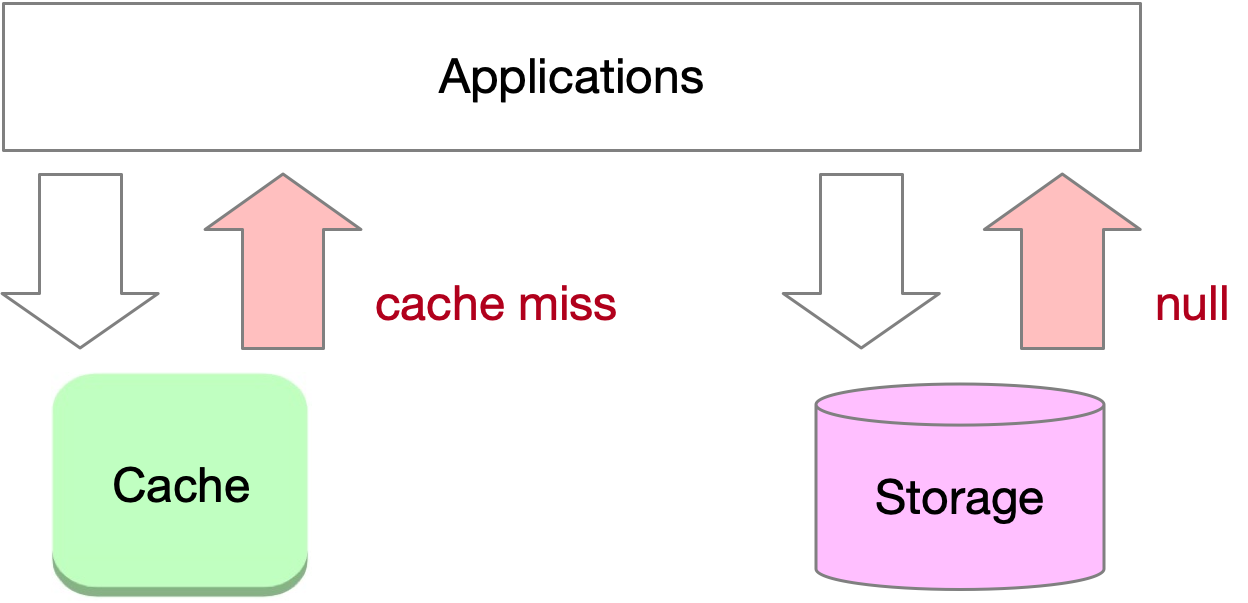
A common example of cache penetration occurs when numerous users try to query non-existent orders on a website within a short period. Large websites typically implement protective measures to mitigate this issue.
To mitigate this, store a placeholder value in the cache to represent non-existent data. Subsequent requests for the same non-existent data will hit the cache instead of the data store. Set an appropriate TTL for these placeholder entries to prevent them from occupying cache space indefinitely.
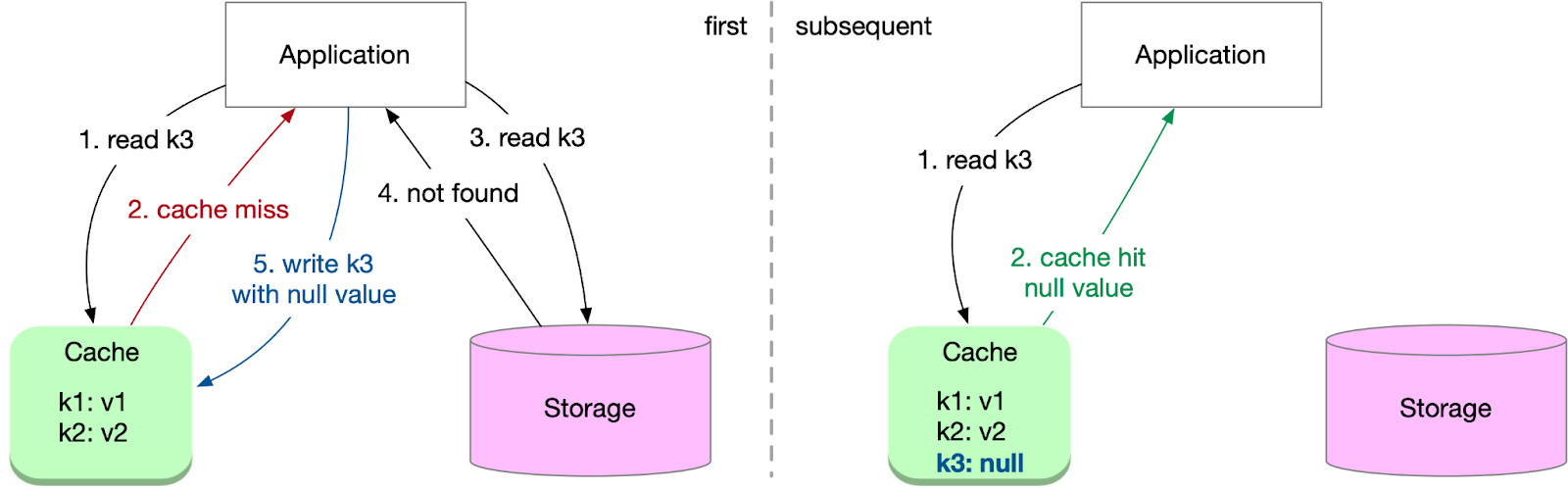
While this method is simple and effective, it can consume significant cache resources if the application frequently queries a large number of non-existent keys.
Another solution involves using a bloom filter, a space-efficient, probabilistic data structure that tests whether an element belongs to a set. By using a bloom filter, the system can quickly identify non-existent data, reducing cache penetration and unnecessary data store requests.
When a record is added to storage, its key is also recorded in a bloom filter. When fetching a record, the application first checks whether the key exists in the bloom filter. If the key is absent, it won’t exist in the cache or storage either, and the application can return a null value directly. If the key is present in the bloom filter, the application proceeds to read the key from the cache and storage as usual. Since a bloom filter sometimes returns a false positive, a small number of the cache reads will result in a cache miss.
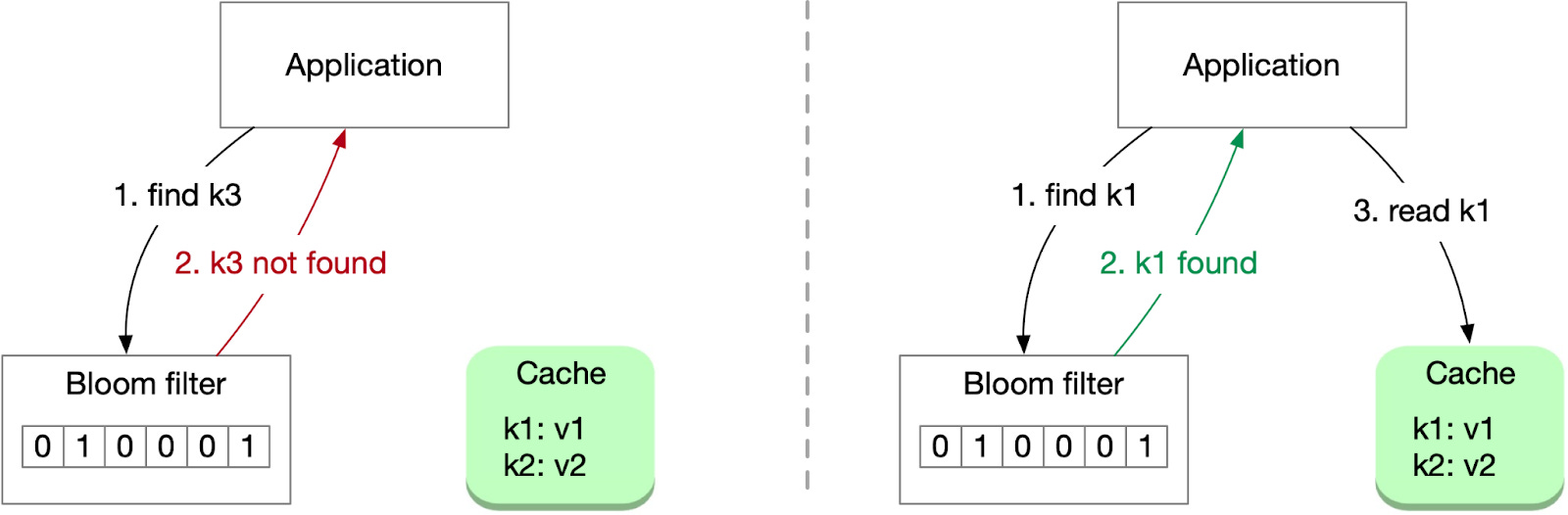
The challenge of using a bloom filter lies in its capacity limitations. For instance, 1 billion keys with a 1% false positive rate would require approximately 1.2 GB of capacity. This solution is best suited for smaller data sets.
Traffic Pattern Challenges
Hot key problem
The hot key problem occurs when high traffic on a single key results in excessive traffic pressure on the cache node, potentially leading to performance issues.
In a distributed cache system, keys are shared across different nodes based on a sharding strategy. Traffic for each key can vary greatly, with some keys experiencing exceptionally high traffic. As illustrated in the diagram below, substantial traffic for keys like “key12” and “key15” could potentially exceed the resource capacity of node 1.
For instance, when tweets are distributed in the cache system by their IDs, and a few of them become popular quickly, the corresponding cache node experiences increased traffic, possibly surpassing its resource capabilities. Hot key issues can arise in various scenarios, such as operational emergencies, festivals, sports games, flash sales, etc.
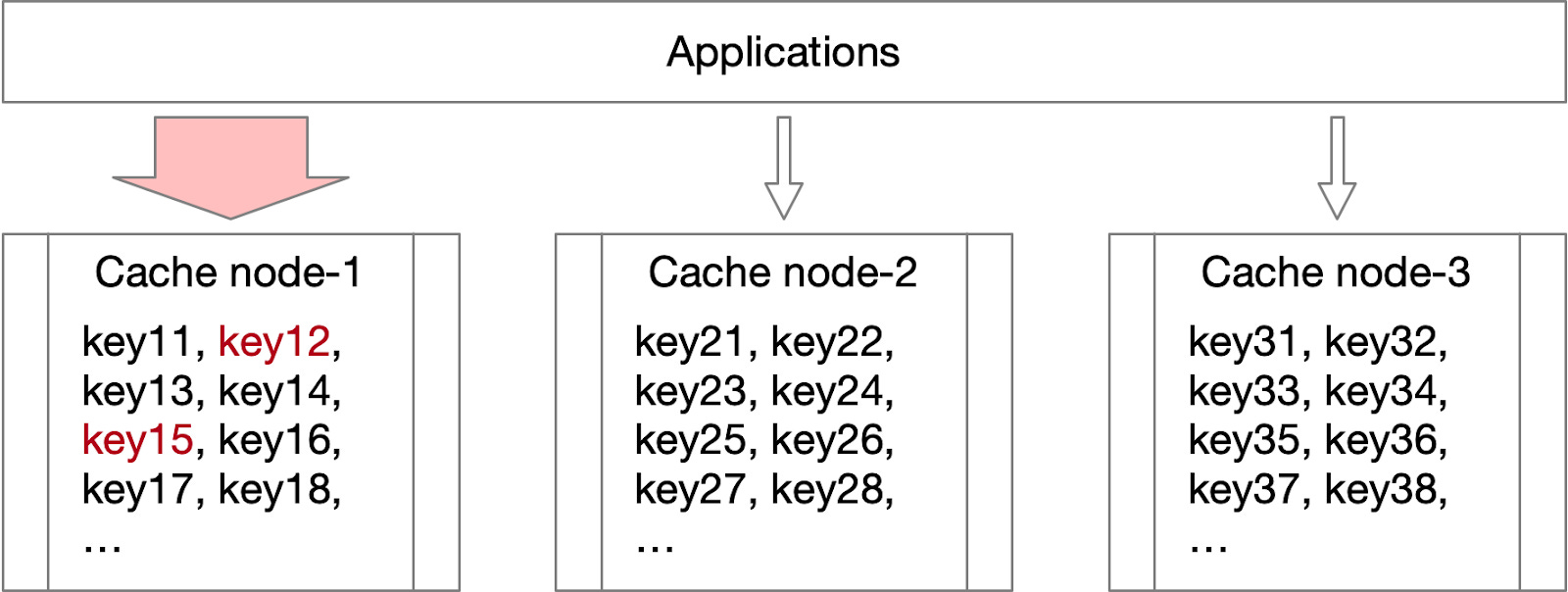
Hot key in distributed cache
To address this problem, two steps are necessary:
-
Identify the hot keys.
-
Implement special measures for these keys to reduce traffic pressure.
In step 1, for predictable events like important holidays or online promotions, it is possible to evaluate potential hot keys beforehand. However, for emergencies, advance evaluation is not feasible. One solution is to conduct real-time traffic analysis to promptly detect emerging hot keys.
In step 2, there are several potential solutions:
- Distribute traffic pressure across the entire cache system. As illustrated in the diagram below, split “key12” into “key12-1”, “key12-2”, up to “key12-N”, and distribute these N keys across multiple nodes. When an application requests a hot key, it randomly selects one of the suffixed keys, enabling traffic to be shared across many nodes and preventing a single node from becoming overloaded.
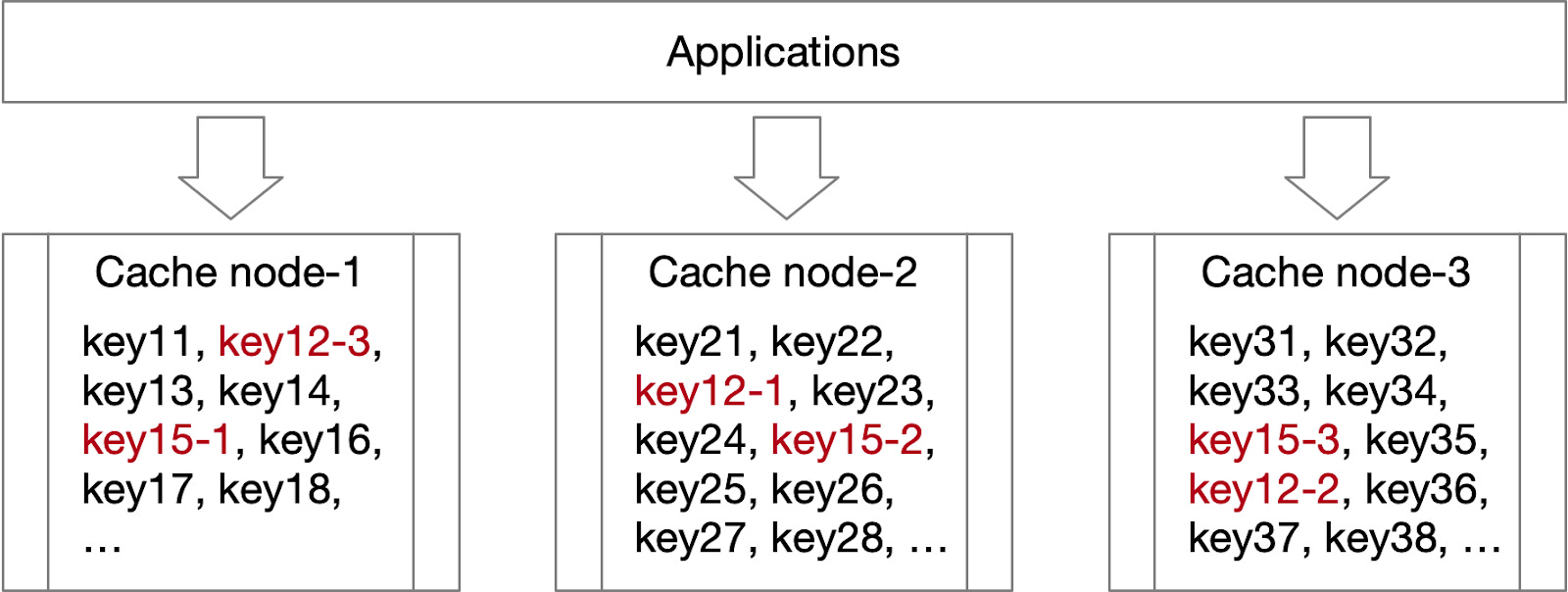
If numerous hot keys exist, real-time monitoring can enable the cache system to expand quickly, reducing the traffic impact.
As a last resort, applications can store hot keys in a local cache, decreasing traffic to the remote cache system. This approach alleviates the pressure on the cache nodes and helps maintain overall system performance.
Large key problem
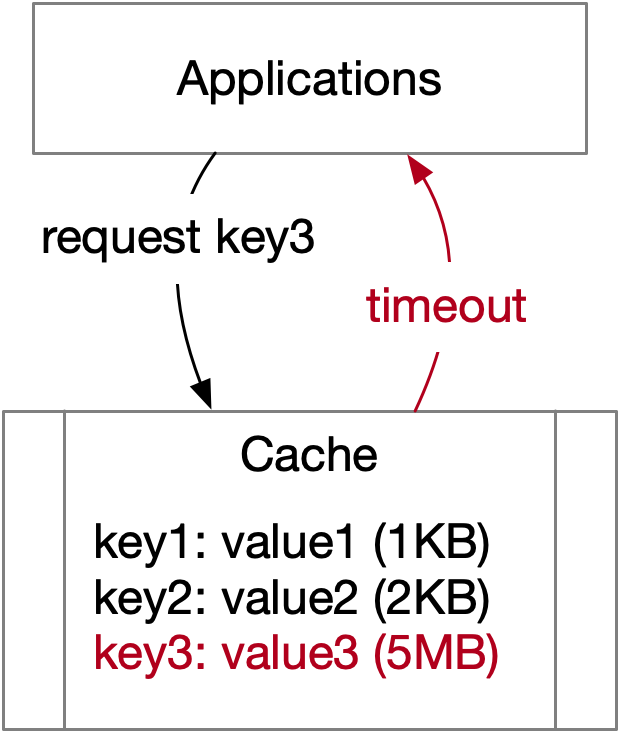
When the value size of a key is significantly large, it can result in access timeouts, leading to the large key problem.
The impact of the large key problem is more severe than it may initially seem:
-
Frequent access to large keys can consume significant network bandwidth, leading to slow lookup performance.
-
Any partial update of a large key will result in the modification of the entire value, further contributing to performance issues.
-
If a large key becomes invalid or is evicted from the cache, reloading it from storage can be time-consuming, leading to additional slow query performance.